Have you ever wondered how an AI can create a stunning image or write a poem? The process is surprisingly similar to baking a cake, especially when you don’t have a recipe. In this post, we’ll explore how the simple act of baking can help us build intuition for how machine learning works.
Baking a cake
Imagine you have all the ingredients and tools necessary but no recipe. Can you still figure out how to bake a cake?
How do we learn to bake a cake without a recipe?
We could try many different options. We experiment. We mix ingredients, change the oven temperature, and adjust the baking time. Each attempt is a new experiment with a specific set of decisions. Each decision on the amount of ingredients, temperature, baking time, humidity etc., is a variable to take into account. e.g., 200g of flour, 220g of sugar, 2 eggs, 35 mins in the oven, 180º…
Consider a couple of scenarios:
- Experiment 1:
- High heat (250º), short time (10 mins).
- Result: Burnt on the outside and raw on the inside.
- Experiment 2:
- Low heat (120º), long time (2 hours).
- Result: Dry and hard.
The combinations seem endless, but are they? Can we create enough experiments to find the ideal heat and ideal time? How many experiments do we need to find the right temperature? Can we start with 5 and derive some information? For example: min, 50º, 100º, 150º, max. And the same with the time? For example: 10 mins, 30 mins, 60 mins, 90 mins, max.
| Temp \ Time | 10 mins | 20 mins | 30 mins | 40 mins |
|---|---|---|---|---|
| Min | ❄️ | ❄️ | ❄️ | ❄️ |
| 100º | 🫠 | 🫠 | 🫠 | 🍰 |
| 150º | 🫠 | 🫠 | 🍰 | 🪨 |
| 200º | 🫠 | 🍰 | 🪨 | 🔥 |
| Max | 🪨 | 🔥 | 🔥 | 🔥 |

This is an analogy for how a machine learning model learns. When we train the model, we test millions or billions of different combinations of its internal settings (called parameters) to find the combination that works best for a specific task.

In a virtual world, where testing every combination is cheap, the operations can scale and be tested much faster and more efficiently than in any other environment. It is the perfect environment to empirically test without having to understand the underlying reasoning of why something works.
At the end, how many possible settings exist for an oven to bake a cake? And to write in a language?

How do we know if our cake is good?
What guides our improvements?
For a cake, we need clear metric for success. Is it delicious? Is the texture right? Does it look good? These metrics guide our next attempts.
Is there a way to gather an enormous amount of feedback on the cake, knowing the settings we used to cook each of those cakes?
Let’s do a thought experiment. Let’s imagine we have access to all the kids in a school to let them all try a piece of multiple cakes and get their feedback.
What do most of the kids testing the cake like about the cake? Is there a group of them that likes the cake more than others? Are those with more sugar more likeable? Is more chocolate the key? What does the average of them like? Are there clusters of people that prefer a type of cakes more?

Once we have gathered all the feedback from the kids, we can analyze the results and use the average of a 1 to 10 evaluation of “how likely they would ask for that cake another day?” as the key metric to understand which of the cakes performed best. Then, we can use the cooking parameters of the oven that had the best result, slightly change them and repeat the evaluation from the kids to look for an even more optimized outcome. In an endless loop. Until we find the perfect cake.
This cycle of baking, getting feedback, and adjusting the recipe is the core of how a machine learning model learns.

Instead of kids tasting cakes, we show the algorithm thousands of examples where we already know the correct answer. We then compare the machine’s “attempt” to these known examples to see how close it got. It’s like comparing our experimental cake to a “perfect” version: the further away the result is from the goal, the more we know we need to adjust our settings.
We then use a metric to evaluate this success. In the AI world this is called a loss function. It can be the likelyness to ask that cake again, or if the prediction of the machine learning model is correct. It’s just a mathematical way to tell the AI how well it’s doing. The goal is always to minimize “error” or “cost” that the function yields and maximize accuracy, just as we try to bake a cake that maximizes deliciousness.
The idea is to perform a search for the optimal set of parameters in a process known as training.
What are the tools and material for baking a machine learning model?
Raw material, flour, sugar, chocolate, enters an oven and produces a product, the cake.
Data is the raw material for machine learning.
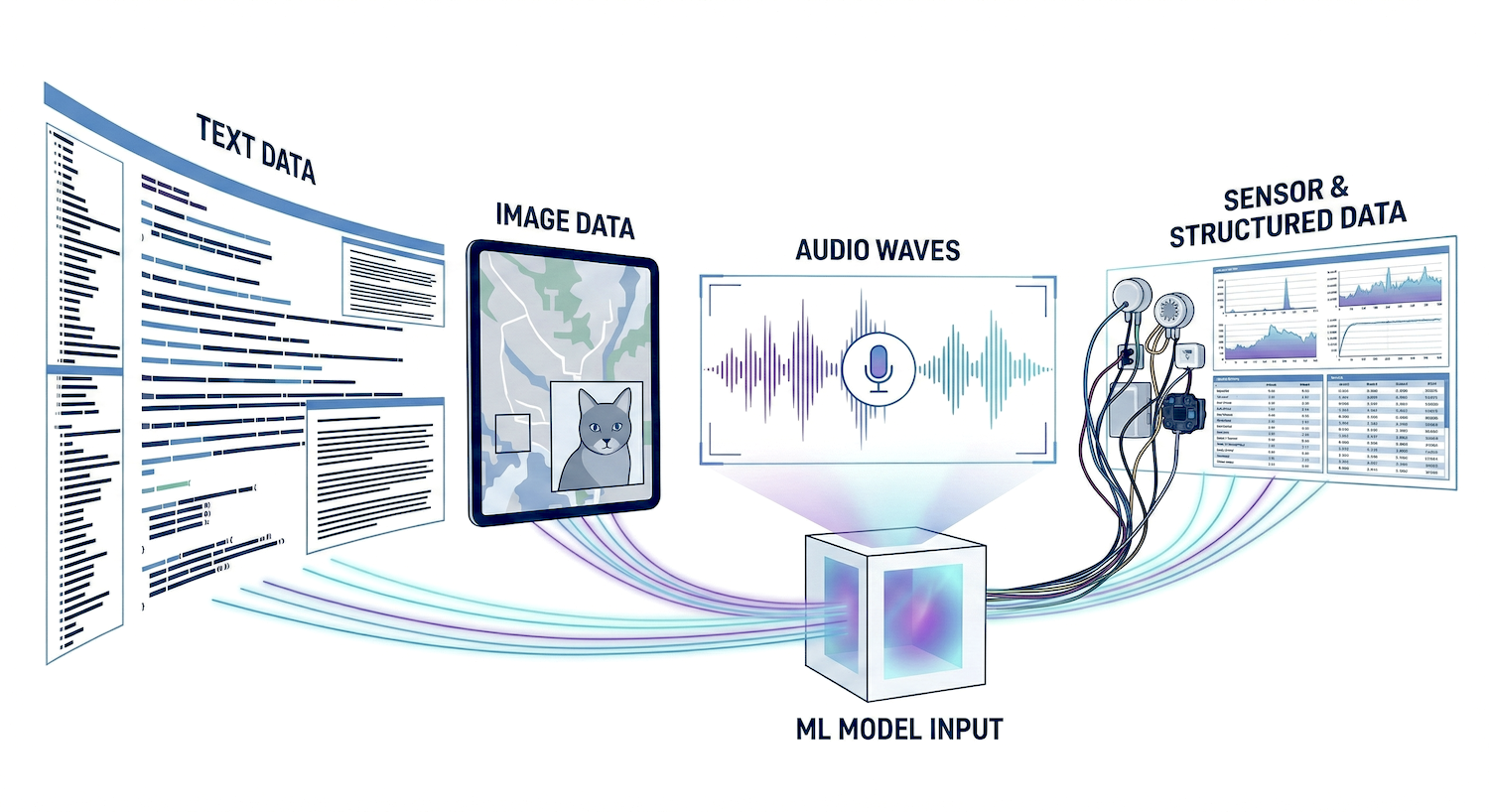
Data, the raw material, enters a machine learning model and produces a product, in the form of data. e.g. an image (which is data), get’s into the model and produces an output in the form of a number from 0 to 9.

The ingredients (our input data) are fed into the oven (the AI model), which processes them and produces a finished product (the output data). This could be a prediction, a classification, a translation, or even a newly generated image.
Why is it so hard to get machine learning right?
Now that we understand how machine learning models are created, let’s consider how they can fail.
- Machines replace repetitive physical tasks.
- AI replaces repetitive intellectual tasks.

For centuries, we have built machines to automate physical labor and produce the exact same product again and again. These machines are predictable, a cake created with a machine and a recipe will consistently have the same taste and texture. Because the raw materials and the process remain constant, variability is low. As a result, our tolerance for error is minimal and our expectations for repeatability are high.
Intellectual tasks are much harder to define and measure than physical ones. It is often unclear exactly how these tasks should be performed or how repeatable the results can be (e.g. the task of extracting information from a document might seem straightforward, but every document and topic has its own unique nuances).
A traditional machine is like a baker with a perfect, unchanging recipe for one type of cake. An AI is like asking a oven to consistently produce a delicious result, even when the flour is a bit different, the eggs are a different size, and the customer asks for a slightly different flavor.
Might be feasible? yes, but it’s much harder.

Is really chocolate the answer? Can the model cook other things?
If we only train our machine learning model only to create chocolate cakes, it might become an expert at making chocolate cakes but fail spectacularly when asked to bake a vanilla cake. If we ask the model to bake a pizza instead of a cake, would it work? The cake recipe and experience will not be very helpful.
If a machine learning model that is trained on a very specific dataset, cannot generalize to new, unseen data. This phenomenon is known as overfitting. The model has effectively memorized the “recipe” for chocolate cakes but hasn’t learned the underlying principles of baking. Generalization is key for model that performs well.
Do we trust the kids?
What if all the kids in the school have a preference for sweetness? After all, they are kids; what if adults prefer cakes that are less sweet? You might end up with a cake that is incredibly sweet, but not enjoyable for a wider audience.
This is analogous to biased training data, which can lead to AI models that perform poorly for certain situations due to the lack of testing data in that scenarios. The kids’ preference for sweetness introduces a bias. A model trained on this feedback will conclude that more sugar is always better. To ensure fairness and accuracy, the data used for training must be representative of the full population of cake-eaters.
Techniques like cross-validation can be used to check if the model can generalize. Instead of just one group of kids tasting the cake, we could try it with multiple, different groups (e.g. kids, adults, elders). If all groups like the cake, we can be more confident that our recipe is genuinely good and not just tailored to one specific palate.
This can also happen if the friction to answer the questions about the cake is too high (they have to fill a long form) and/or our kids and adults too lazy. If we ask three kids to rate a cake and they all give it a similar score, their agreement is high. If their scores are wildly different, the feedback is noisy and less trustworthy and might misalign the model with what we expect from it. The inter-annotator agreement helps us understand if our evaluators are reliable.
Are we asking the correct questions?
Imagine we set the metric for a “good” cake is its weight. We optimize the recipe to produce the heaviest cake possible. We will get a dense, heavy cake. We succeeded on the metric, but failed at the goal. This goal misalignment happens when the metric we optimize (weight) doesn’t align with our true goal (deliciousness). This is also known as “reward hacking”, where the AI finds a shortcut to maximize its reward without achieving the intended outcome.
Are the ingredients good enough?
We use stale flour, rotten eggs, or sugar that’s clumped up with moisture. No matter how perfect our recipe (the model) is, the cake will be terrible.
If the data used to train a model is bad, contains errors, or is irrelevant, the model will make poor predictions. The quality of the output is entirely dependent on the quality of the input. During the training process is crucial to perform a good data cleaning, a meticulous work of fixing or removing errors, handling missing values, and standardizing formats in the dataset. It’s the equivalent of sifting the flour, discarding bad eggs, and ensuring all measurements are precise before baking.
This principle is often referred to as “garbage in, garbage out”. No matter how sophisticated the model, it cannot create a good result from poor-quality raw materials. Automated checks and rules to ensure the data is valid and reliable is crucial. For example, a validation rule could check the weight and volume of the chocolate. This ensures the ratio is reasonable and the data makes sense before it’s fed to the model.
Can I trust the oven? And the suppliers?
Even if the oven produces a perfect cake, we have no idea how. We haven’t learned a thing about it. If it suddenly produces a terrible cake, we have no easy way of understanding why because the process is a a black box mystery. Some time a tiny, often imperceptible change can cause the end product to be completly wrong.
Most powerful models tend to be “black boxes,” meaning their internal logic is incredibly complex and not intuitive to humans. Interpretability and Explainability (XAI) is a field dedicated to creating methods that help us understand why a model makes a specific decision. It’s like installing a glass window on the oven to see how the cake is baking and understand the process, rather than just hoping for the best.
This can help us to understand when something goes wrong due to a change in the real world. If our chocolate supplier changes their recipe, our model, which was trained on the old chocolate, might start producing subpar cakes. This is called model drift. Continuously watching the model’s performance in the real world, helps to alert us when it’s time to retrain the model with new ingredients.
This is also key in case of a deliberate change to the input data to fool our model, and adversarial attack. It’s like a saboteur adding a few grains of a substance that looks exactly like sugar but ruins the cake’s chemistry, causing the model to fail in a surprising and unpredictable way.
Closing
By viewing machine learning models as tools similar to an oven, it becomes easier to understand how things can go wrong. By demystifying these tools, we can leverage years of risk management from various industrial settings to professionalize the evaluation and productionalization of models.
Whether you’re new to the subject or an expert looking for a fresh way to explain your work, I hope this analogy has provided some food for thought 🍰.